ML
Linear Regression: 回归
Logistics Regression:分类
Sigmoid:将任意实数输入映射到(0,1)。
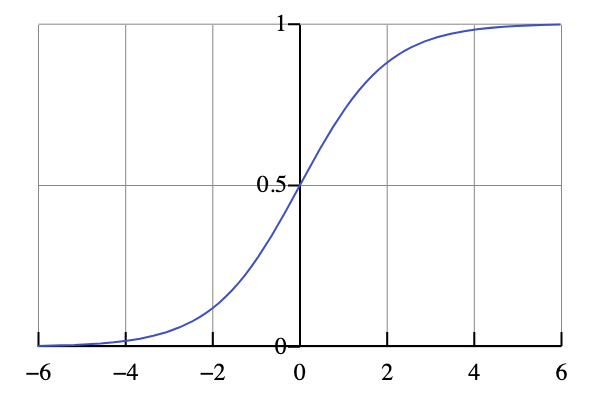
例子:体重和血糖
Linear Regression:体重x,血糖y。y=wx+b学习输入,做回归。
Logistics Regression:体重x;0血糖正常,1血糖高。
- 本质上还是线性学习y=wx+b。
- 加上写死的Sigmoid函数把y解释为概率。
- 此处的y并不是血糖值,没有实际意义,是一个逻辑得分。用sigmoid映射为概率才有实际意义。
并不是所有的分类都给出概率。给出概率,可解释性高,是Logistics Regression的优点。
ReLU(Rectified Linear Unit)和 Sigmoid 都是 激活函数(activation function)
线性分类:
- Logistics Regression,LNN。
LNN是最简单的神经网络。
输入+线性变换[+输出层]输入+线性变换+Sigmoid == Logistics Regression
- SVM,Perceptron:学习一个超平面做二分类。
CNN:输入+nx[卷积层+激活+池化]+线性变换+输出层
有各种经典模版。如LeNet-5。
RNN:输入+nx[RNN隐藏层]+线性变换+输出层
FNN:nxF[线性变换+激活函数]
seq2seq中:
FNN:只用xi预测yi
RNN:维持一个state变量(ai-1),和每一个输入xi一起,参与每一个字yi的预测
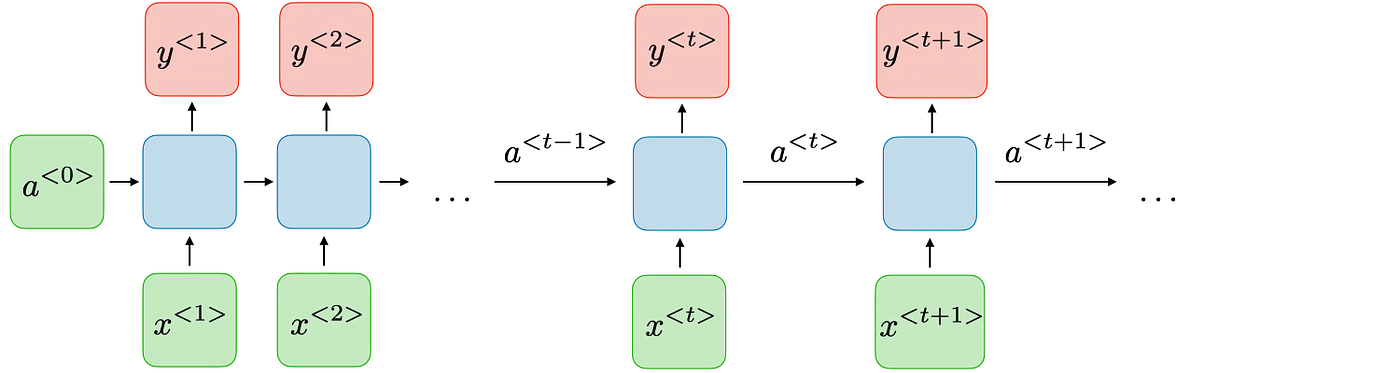
RNN:一个state存储所有之前的信息,旧信息易丢失。
LSTM:用memory cells 和 3 x gates更新state,不会轻易丢失有用的信息,对长序列表现好。
Transformer:
- Attention:不再传递状态,同时看序列中所有词,决定每个词的权重。
- 由于不再序列计算不再依赖顺序关系,序列里所有词可以同时计算,可以利用GPU的并行计算能力。
- Encoder = Embedding + 上下文理解(通过自注意力)
命名实体识别 (NER)
BERT使用基于注意力的Encoder,把每个词都编码成 [词本义]+[词上下文信息] 的向量,然后直接进行分类。
- CNN(CV), RNN/LSTM(NLP)
- Attention/Transformer
- BERT
- LLM