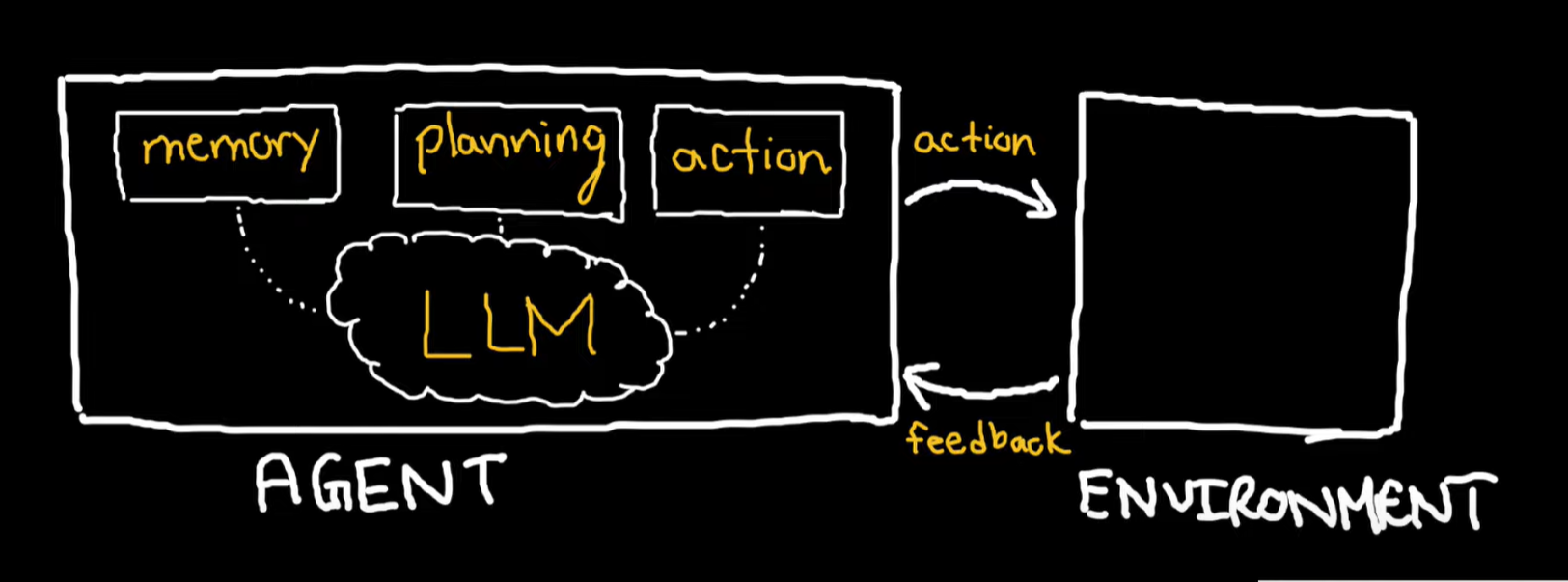
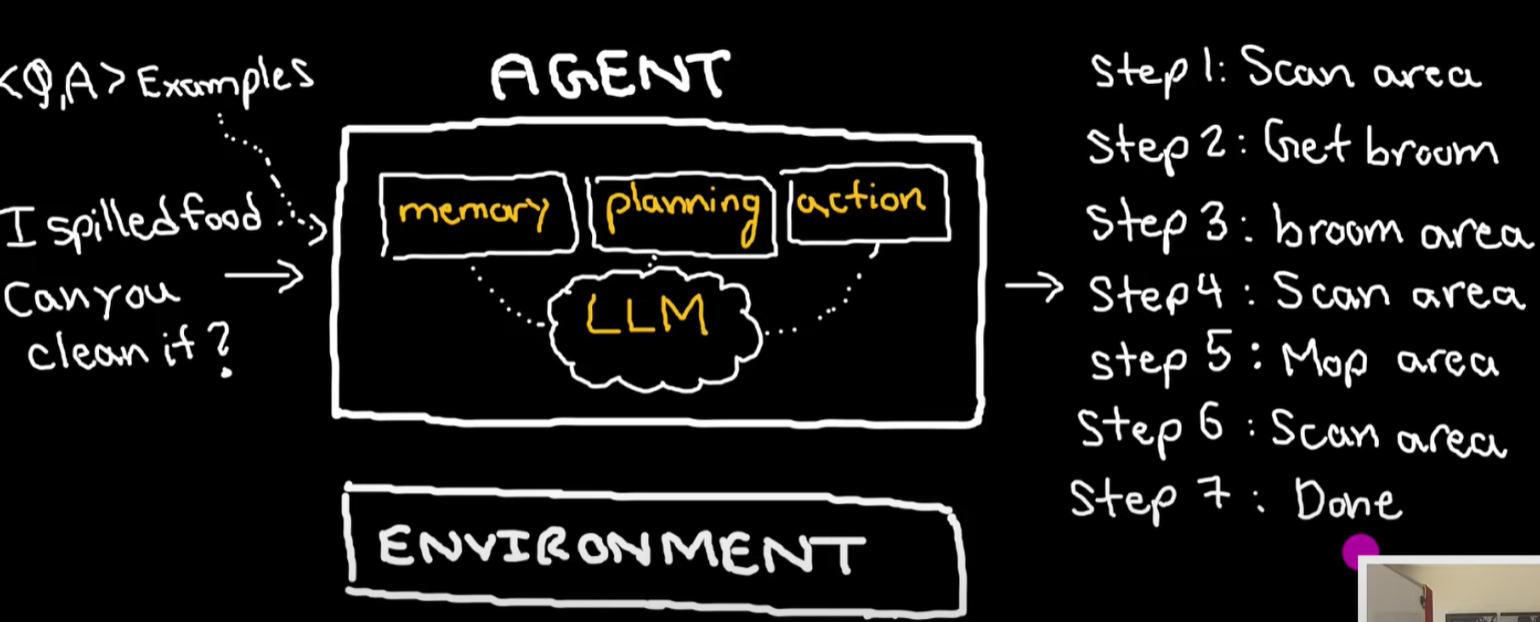
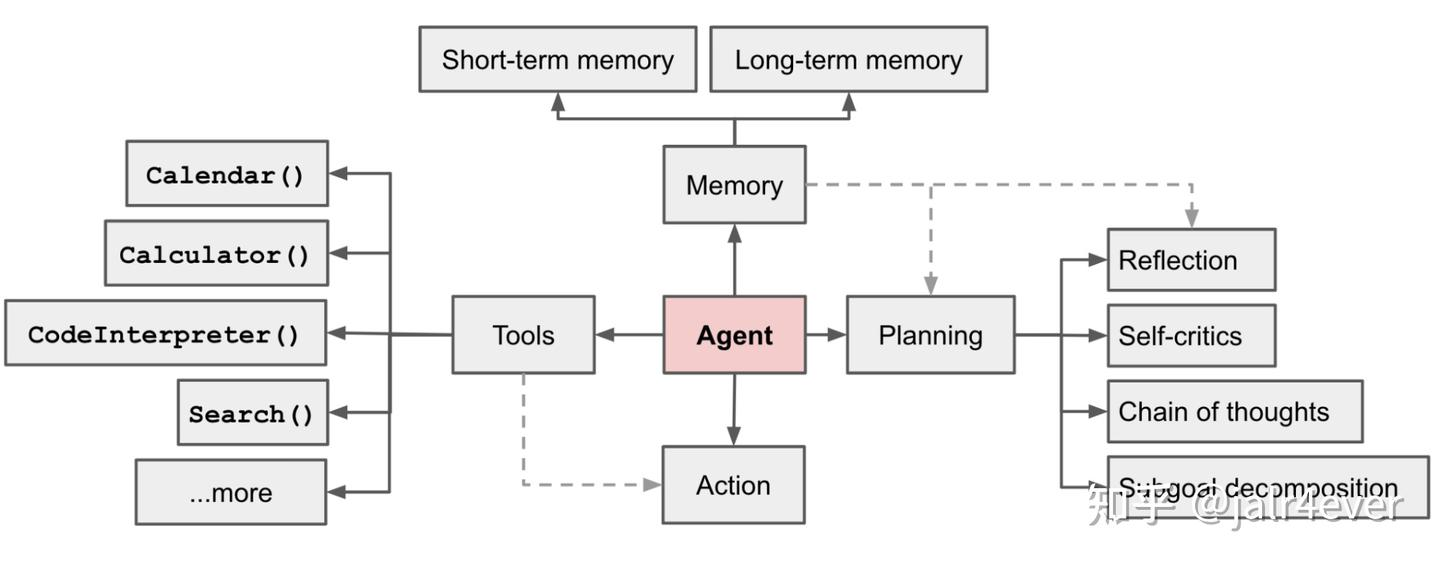
agent
RAG:
给大模型外挂一个知识库。(Knowledge Base就是一种实现)
- 检索数据源,拼接上下文(拼进prompt)。
- 每次调用都会重复记入token。
- RAG每次只会把检索出的一小部分拼进prompt。(~top-5)
- 检索方式是将文本转为向量,然后计算相似度。(类似KNN)(Knowledge Base使用Open Search实现)
Agent vs RAG:
interact with environment, dynamic interact
Token:
- 模型处理文本的最小单元。
- 一个单词可能被拆成多个token。不能和字节简单对应。
- 价格:
- 成本上 output token 比 input token 高。
- gpt & claude 收费 output 比 input 高。
Rerank:'cohere.rerank-v3-5:0’
- 应用于二阶段检索架构中,用以对初筛的候选文档精细排序。(通常成本较高)
- 是一类功能模型的总称,不限定架构。(具体实现可能是BERT,LLM)
- Embedding - KNN - Reranker 是一种主流做法。
vLLM:部署时使用。目前最先进的推理引擎之一
- 类似Flask应用的Gunicorn。
- 模型训练和推理都需要使用GPU。